Music Genre Classification
A comparative study of machine learning and deep learning architectures for automatic audio classification using the GTZAN dataset.
CSE342
Statistical Machine Learning
89%
Best Accuracy (RCNN)
10
Music Genres
1,000
Audio Samples
5
Models Compared
Model Performance
Decision Tree
Traditional ML
53%
Logistic Regression
Traditional ML
66%
KNN
Traditional ML
67%
CNN
Deep Learning
87%
RCNN
Deep Learning
89%
Genre Spectrograms
Mel-spectrograms visualize audio frequency content over time. Click play to listen to each sample.
blues
blues.00000.wav
blues.00001.wav
blues.00002.wav
classical
classical.00000.wav

classical.00001.wav
classical.00002.wav
country
country.00000.wav
country.00001.wav
country.00002.wav
disco
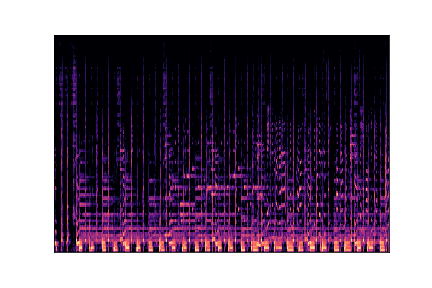
disco.00000.wav
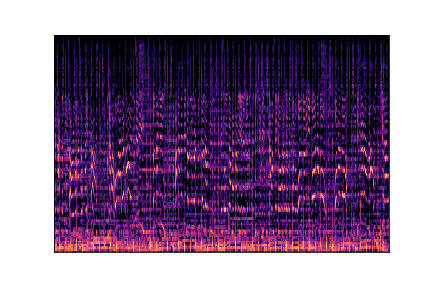
disco.00001.wav
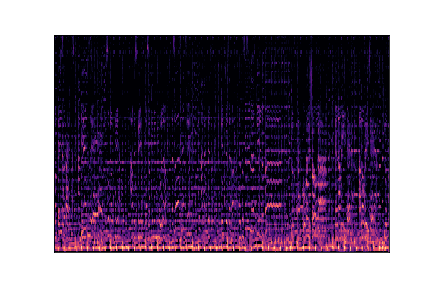
disco.00002.wav
hiphop
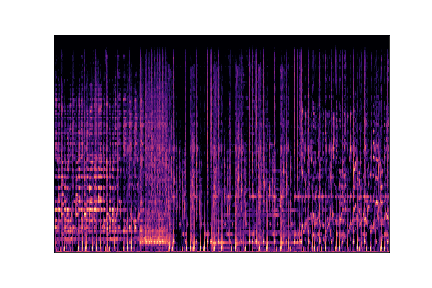
hiphop.00000.wav
hiphop.00001.wav
hiphop.00002.wav
jazz
jazz.00000.wav
jazz.00001.wav
jazz.00002.wav
metal
metal.00000.wav
metal.00001.wav
metal.00002.wav
pop
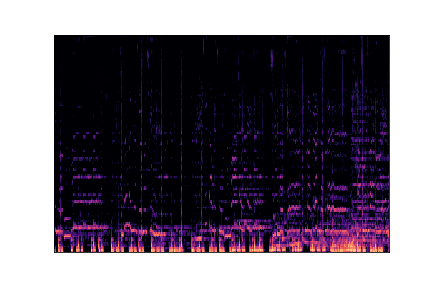
pop.00000.wav
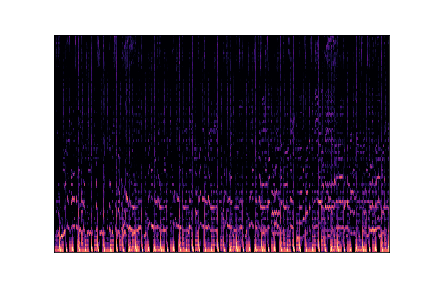
pop.00001.wav
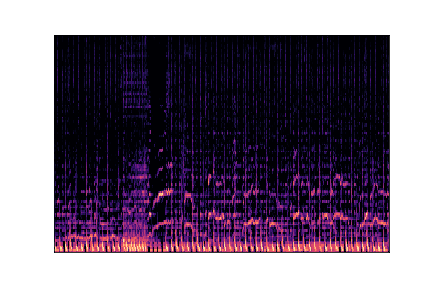
pop.00002.wav
reggae
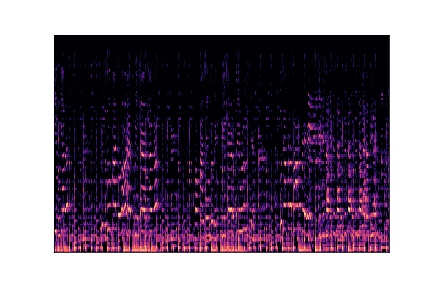
reggae.00000.wav
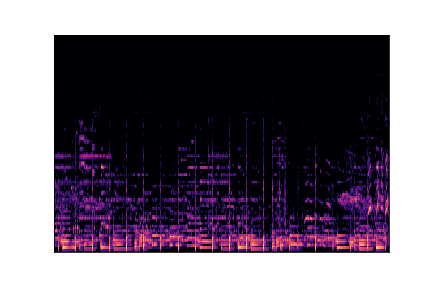
reggae.00001.wav
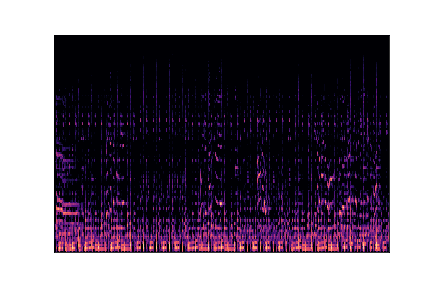
reggae.00002.wav
rock
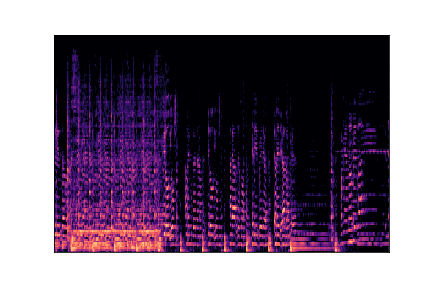
rock.00000.wav
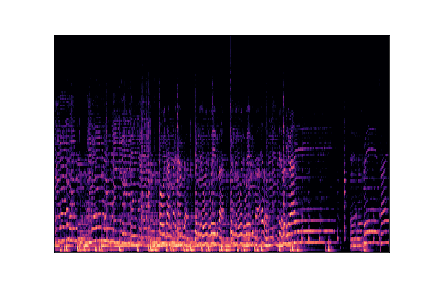
rock.00001.wav
rock.00002.wav
Methodology
Dataset
GTZAN Genre Collection with 1,000 audio samples across 10 genres, each 30 seconds long, segmented into 3-second clips.
Feature Extraction
MFCCs, spectral centroid, zero-crossing rate, tempo, and mel-spectrograms for visual representation.
Models
KNN, Logistic Regression, Decision Trees for traditional ML. CNN and RCNN for deep learning approaches.